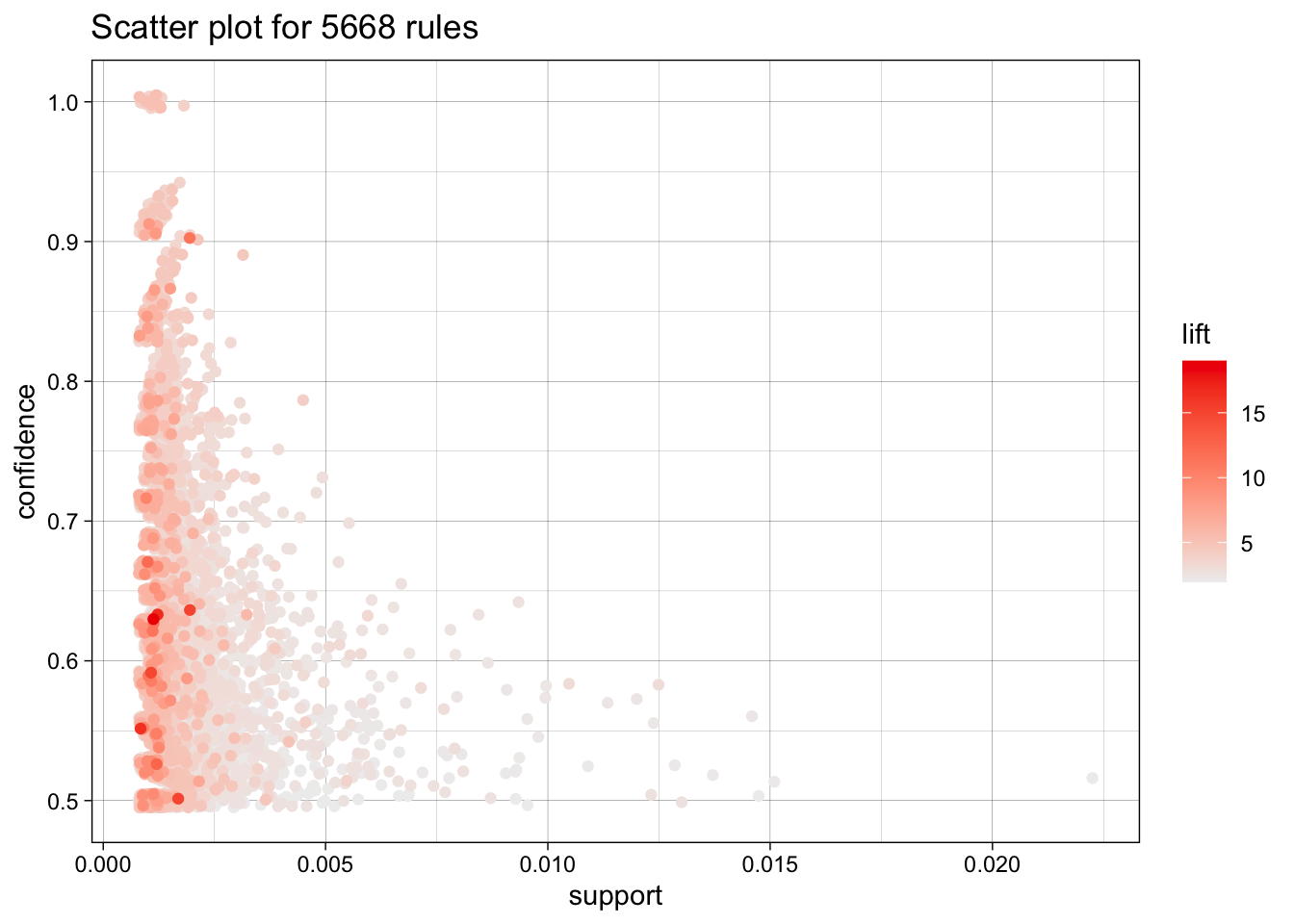
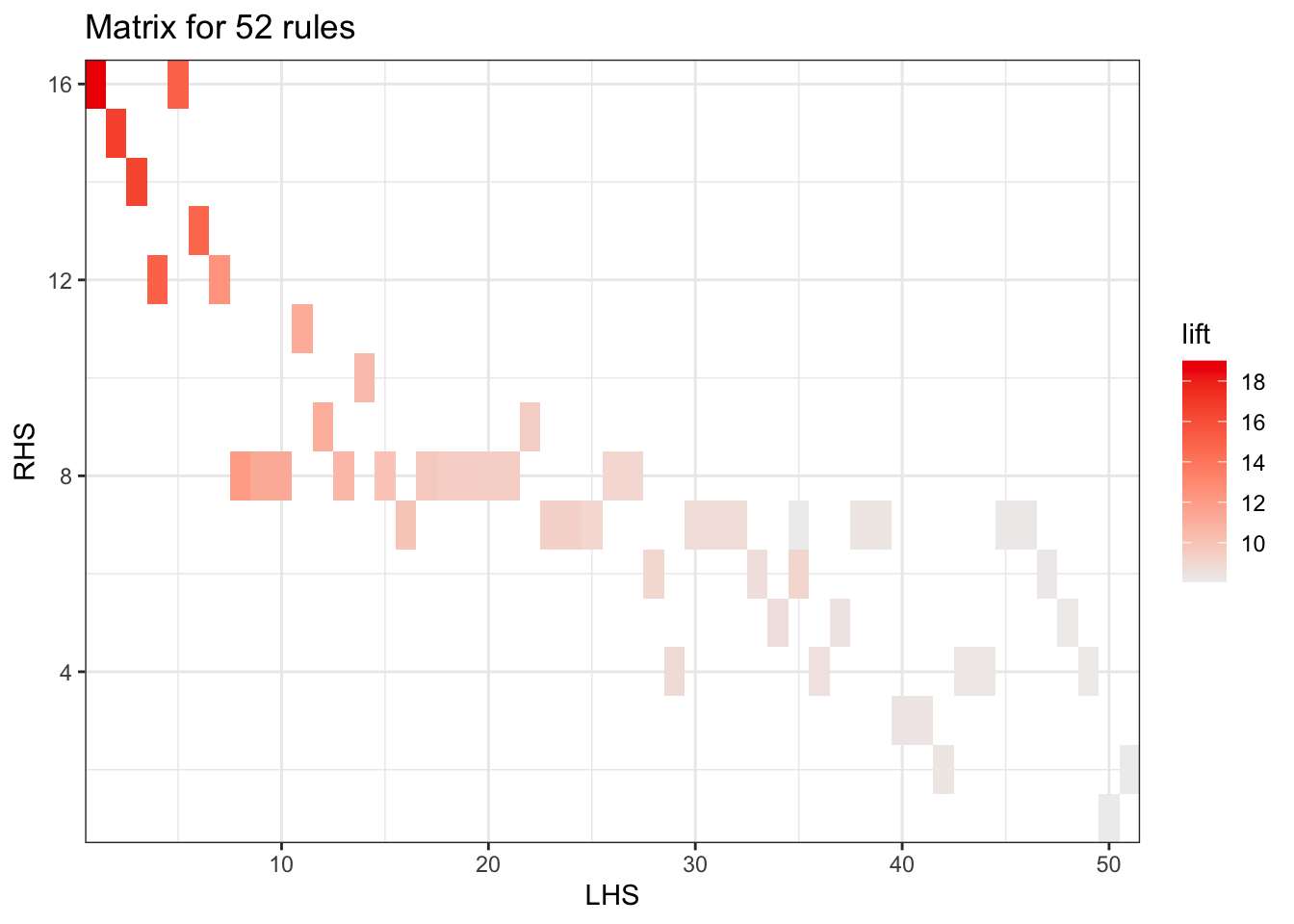
Itemsets in Antecedent (LHS)
[1] "{Instant food products,soda}"
[2] "{soda,popcorn}"
[3] "{flour,baking powder}"
[4] "{ham,processed cheese}"
[5] "{whole milk,Instant food products}"
[6] "{other vegetables,curd,yogurt,whipped/sour cream}"
[7] "{processed cheese,domestic eggs}"
[8] "{tropical fruit,other vegetables,yogurt,white bread}"
[9] "{hamburger meat,yogurt,whipped/sour cream}"
[10] "{tropical fruit,other vegetables,whole milk,yogurt,domestic eggs}"
[11] "{liquor,red/blush wine}"
[12] "{other vegetables,yogurt,whipped/sour cream,cream cheese }"
[13] "{yogurt,whipped/sour cream,hard cheese}"
[14] "{tropical fruit,root vegetables,other vegetables,whole milk,rolls/buns}"
[15] "{tropical fruit,whole milk,yogurt,sliced cheese}"
[16] "{other vegetables,butter,sugar}"
[17] "{whole milk,whipped/sour cream,hard cheese}"
[18] "{other vegetables,hard cheese,domestic eggs}"
[19] "{tropical fruit,other vegetables,whipped/sour cream,fruit/vegetable juice}"
[20] "{tropical fruit,onions,yogurt}"
[21] "{tropical fruit,other vegetables,yogurt,domestic eggs}"
[22] "{butter,yogurt,pastry}"
[23] "{whole milk,butter,hard cheese}"
[24] "{tropical fruit,other vegetables,butter,fruit/vegetable juice}"
[25] "{whole milk,curd,yogurt,cream cheese }"
[26] "{tropical fruit,other vegetables,hard cheese}"
[27] "{other vegetables,whole milk,whipped/sour cream,napkins}"
[28] "{citrus fruit,whole milk,cream cheese }"
[29] "{tropical fruit,other vegetables,frozen fish}"
[30] "{butter,yogurt,hard cheese}"
[31] "{curd,yogurt,sugar}"
[32] "{other vegetables,whole milk,butter,soda}"
[33] "{whole milk,cream cheese ,sugar}"
[34] "{frozen vegetables,specialty chocolate}"
[35] "{citrus fruit,other vegetables,whole milk,cream cheese }"
[36] "{tropical fruit,whipped/sour cream,shopping bags}"
[37] "{citrus fruit,tropical fruit,grapes}"
[38] "{other vegetables,butter,hard cheese}"
[39] "{whole milk,butter,sliced cheese}"
[40] "{citrus fruit,other vegetables,soda,fruit/vegetable juice}"
[41] "{tropical fruit,other vegetables,whole milk,yogurt,oil}"
[42] "{tropical fruit,grapes,fruit/vegetable juice}"
[43] "{frankfurter,tropical fruit,domestic eggs}"
[44] "{tropical fruit,whole milk,yogurt,frozen meals}"
[45] "{other vegetables,curd,yogurt,cream cheese }"
[46] "{root vegetables,whole milk,flour}"
[47] "{citrus fruit,whole milk,sugar}"
[48] "{tropical fruit,other vegetables,misc. beverages}"
[49] "{ham,tropical fruit,other vegetables}"
[50] "{citrus fruit,grapes,fruit/vegetable juice}"
[51] "{whole milk,whipped/sour cream,rolls/buns,pastry}"
Itemsets in Consequent (RHS)
[1] "{tropical fruit}" "{citrus fruit}"
[3] "{root vegetables}" "{pip fruit}"
[5] "{fruit/vegetable juice}" "{domestic eggs}"
[7] "{whipped/sour cream}" "{butter}"
[9] "{curd}" "{beef}"
[11] "{bottled beer}" "{white bread}"
[13] "{cream cheese }" "{sugar}"
[15] "{salty snack}" "{hamburger meat}"