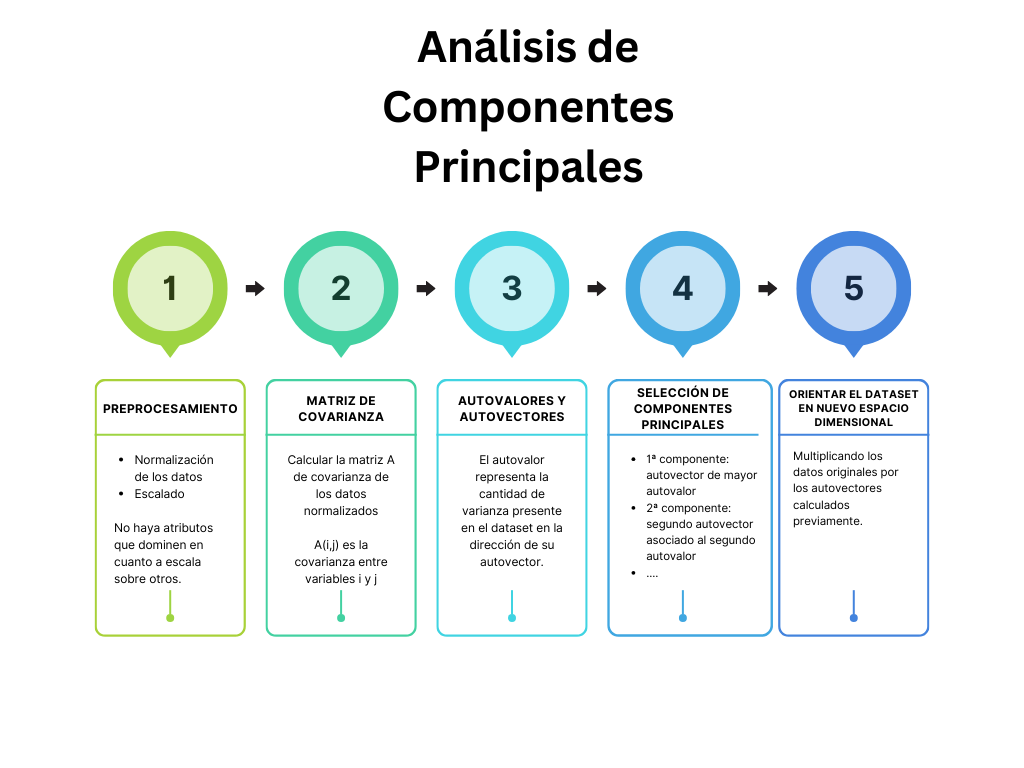
{kind=link}
ComponPrinc <- prcomp(dataset, center=TRUE, scale=TRUE)8 Análisis de Componentes Principales
PCA (Principal Component Analysis) es una técnica de reducción de dimensión, que permite pasar de una gran cantidad de variables interrelacionadas a unas pocas variables incorreladas entre sí llamadas componentes principales.
Pearson a finales del siglo XIX desarrolló esta técnica que Hotelling en los años 30 del siglo XX siguió estudiando y que no se ha popularizado hasta su aplicación en la Ciencia de Datos.
Es un método de aprendizaje no supervisado porque no se trata de predecir una variable respuesta sino de extraer información.
Técnica util para extraer conocimiento de datasets de alto número de variables (multidimensional).
Si tengo 25 variables por ejemplo, hay que considerar \(\binom{25}{2}=300\) posibles coeficientes de correlación. Es difícil visualizar relaciones entre las variables.
Es normal una fuerte correlación: si tomamos demasiadas variables, lo normal es que muchas de ellas estén relacionadas o que midan lo mismo bajo distintos puntos de vista.
Filosofía: PCA consiste en buscar combinaciones lineales de las variables originales que representen lo mejor posible a la variabilidad presente en los datos.
Cuanto mayor sea la variabilidad de los datos (varianza) se considera que existe mayor información.
Las nuevas variables se van construyendo según el orden de importancia en cuanto a la variabilidad total del dataset.
De modo ideal, se buscan \(m < p\) variables que sean combinaciones lineales de las \(p\) originales y que están incorreladas, recogiendo la mayor parte de la información o variabilidad de los datos.
Estas nuevas variables se les llama componentes principales.
8.1 Aplicación
Regresión: El análisis de componentes principales se puede usar como un paso previo para reducir la dimensión y seleccionar variables para realizar una regresión.
Análisis factorial: PCA es una técnica exploratoria. El problema de inferir si las propiedades de reducción de la dimensión encontradas en los datos puede extenderse a la población de la que provienen se estudia mediante el análisis factorial.
8.2 ¿Cuando PCA?
Si las variables originales están incorreladas no se hace PCA.
PCA no requiere la normalidad multivariante de los datos.
PCA identifica aquellas direcciones en las que la varianza es mayor. Estandarizar siempre los datos antes de comenzar.
Al trabajar con varianzas, PCA es sensible a outliers. La detección de outliers con múltiples dimensiones se complica (un hombre que mide 2 metros y pesa 50 kg, ninguno de los dos valores es atípico de forma individual, pero en conjunto se trataría de un caso muy excepcional).
8.3 Reducción de la dimensionalidad
PCA: calcular autovalores y autovectores
Objetivo:
“Main directions of variability”
Reducir la complejidad - reducción de la dimensionalidad
Identificar patrones significativos-interesantes - responsable de variación en un grupo de variables
Los autovectores determinan las direcciones del nuevo espacio de características (variables) y los autovalores su magnitud (longitud - varianza de los datos en los nuevos ejes de características).
PCA tiene sentido si algunos autovalores tienen una magnitud significativamente mayor que el resto (reducir a un subespacio de menor dimensión eliminando las variables menos informativas).
Dos visiones:
- Estudiar individuos (filas)
- Estudiar variables (columnas)
Cuestiones:
Encontrar grupo pequeño de variables que represente a todas las variables
Agrupar individuos usando las variables principales
Usar individuos específicos para comprender mejor las conexiones entre las variables
Reducir un espacio de n dimensiones (n columnas) a un espacio de k dimensiones que resuma la nube de puntos del dataset
Encontar un subespacio en el que las distancias entre los individuos se distorsione lo menos posible
8.3.1 Método
Preprocesamiento: Estandarizar los datos.
Paso 1 - ajuste del modelo
- llamada a la función que calcula los componentes principales - (realizar previamente preprocesamiento)
- calcular autovalores y autovectores de la matriz de covarianza o de correlaciones o usando SVD.
Paso 2 - seleccionar el número de componentes
- cierta subjetividad, pero también es relativamente sencillo
- ordenar los autovalores (descendentes) y escoger sus k autovectores asociados (k es el número de dimensiones del subespacio reducido)
Paso 3 - interpretación al conjunto de componentes principales que hemos seleccionado.
- qué parte de la varianza original de cada covariable es explicada por cada componente.
- construir la matriz \(W\) de proyección de los k autovectores seleccionados
Paso 4 - Transformar el dataset original usando \(W\)
8.3.2 Número de componentes
Gráfico de sedimentación: Realizar un gráfico de \(\lambda_i\) frente a \(i\). Buscar un descenso generalizado en el gráfico.
Suma de varianzas: Seleccionar componentes hasta llegar a una proporción determinada de varianza.
Contrastes de hipótesis: Test de Barlett o Test de Anderson.
8.4 Paquetes en R
Distintas formas en R de calcular las componentes principales
library(stats)- prcomp() -> Es la que vamos a usar en este ejemplo.
- princomp()
library(FactoMineR)- PCA() -> Los valores ausentes se reemplazan por la media de cada columna. Pueden incluirse variables categóricas suplementarias. Estandariza automáticamente los datos.
library(factoextra)get_pca() -> Extrae la información sobre las observaciones y variables de un análisis PCA.
get_pca_var() -> Extrae la información sobre las variables.
get_pca_ind() -> Extrae la información sobre las observaciones.
8.5 Visualización
library(ggplot2) library(factoextra)
fviz_pca_ind() -> Representación de observaciones sobre componentes principales.
fviz_pca_var() -> Representación de variables sobre componentes principales.
fviz_screeplot() -> Representación (gráfico barras) de eigenvalores.
fviz_contrib() -> Representa la contribución de filas/columnas de los resultados de un pca.
- usaremos
prcomp(PCA básico). Requiere los datos brutos que queremos reducir (el dataset) y extraerá los componentes principales.
alternativas - (
princompyprincipal).paquete
factoextra- elegantes visualizaciones basada en ggplot2
8.5.1 Número de componentes
PCA pretende reducir la dimensión de la matriz original en un número menor de variables que describen la mezcla.
¿Cuántas componentes principales calcular? no es sencillo identificar un número de componentes
Herramientas para seleccionar el número de componentes:
Seleccionar componentes que expliquen al menos entre el 70 y el 80% de la varianza original.
Seleccionar componentes que correspondan a valores propios superiores a 1
Observar el punto de inflación en el diagrama de dispersión (scree plot)
8.6 Proyecto USArrests
- Importamos los datos
USArrests #lista los datos originales Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7
Connecticut 3.3 110 77 11.1
Delaware 5.9 238 72 15.8
Florida 15.4 335 80 31.9
Georgia 17.4 211 60 25.8
Hawaii 5.3 46 83 20.2
Idaho 2.6 120 54 14.2
Illinois 10.4 249 83 24.0
Indiana 7.2 113 65 21.0
Iowa 2.2 56 57 11.3
Kansas 6.0 115 66 18.0
Kentucky 9.7 109 52 16.3
Louisiana 15.4 249 66 22.2
Maine 2.1 83 51 7.8
Maryland 11.3 300 67 27.8
Massachusetts 4.4 149 85 16.3
Michigan 12.1 255 74 35.1
Minnesota 2.7 72 66 14.9
Mississippi 16.1 259 44 17.1
Missouri 9.0 178 70 28.2
Montana 6.0 109 53 16.4
Nebraska 4.3 102 62 16.5
Nevada 12.2 252 81 46.0
New Hampshire 2.1 57 56 9.5
New Jersey 7.4 159 89 18.8
New Mexico 11.4 285 70 32.1
New York 11.1 254 86 26.1
North Carolina 13.0 337 45 16.1
North Dakota 0.8 45 44 7.3
Ohio 7.3 120 75 21.4
Oklahoma 6.6 151 68 20.0
Oregon 4.9 159 67 29.3
Pennsylvania 6.3 106 72 14.9
Rhode Island 3.4 174 87 8.3
South Carolina 14.4 279 48 22.5
South Dakota 3.8 86 45 12.8
Tennessee 13.2 188 59 26.9
Texas 12.7 201 80 25.5
Utah 3.2 120 80 22.9
Vermont 2.2 48 32 11.2
Virginia 8.5 156 63 20.7
Washington 4.0 145 73 26.2
West Virginia 5.7 81 39 9.3
Wisconsin 2.6 53 66 10.8
Wyoming 6.8 161 60 15.6- comprobaciones
Primero veremos que las variables no están incorreladas porque en ese caso no tiene sentido realizar la técnica de Análisis de Componentes Principales.
cov(USArrests) Murder Assault UrbanPop Rape
Murder 18.970465 291.0624 4.386204 22.99141
Assault 291.062367 6945.1657 312.275102 519.26906
UrbanPop 4.386204 312.2751 209.518776 55.76808
Rape 22.991412 519.2691 55.768082 87.72916- análisis exploratorio: medias, desviaciones,
mean=apply(USArrests, MARGIN = 2, FUN = mean) #calcula la media de cada columna
mean Murder Assault UrbanPop Rape
7.788 170.760 65.540 21.232 mean[1] #lista la media de la primera columnaMurder
7.788 sd=apply(USArrests, MARGIN = 2, FUN = sd) #calcula la desviación típica de cada columna
sd Murder Assault UrbanPop Rape
4.355510 83.337661 14.474763 9.366385 - estandarizar: la nube de puntas será distinta si la visualizamos en distintas unidades (Km, m, etc.). Estandarizar implica eliminar unidades lo que facilita comparar.
stand2=scale(USArrests,center = TRUE,scale = TRUE)
stand2 Murder Assault UrbanPop Rape
Alabama 1.24256408 0.78283935 -0.52090661 -0.003416473
Alaska 0.50786248 1.10682252 -1.21176419 2.484202941
Arizona 0.07163341 1.47880321 0.99898006 1.042878388
Arkansas 0.23234938 0.23086801 -1.07359268 -0.184916602
California 0.27826823 1.26281442 1.75892340 2.067820292
Colorado 0.02571456 0.39885929 0.86080854 1.864967207
Connecticut -1.03041900 -0.72908214 0.79172279 -1.081740768
Delaware -0.43347395 0.80683810 0.44629400 -0.579946294
Florida 1.74767144 1.97077766 0.99898006 1.138966691
Georgia 2.20685994 0.48285493 -0.38273510 0.487701523
Hawaii -0.57123050 -1.49704226 1.20623733 -0.110181255
Idaho -1.19113497 -0.60908837 -0.79724965 -0.750769945
Illinois 0.59970018 0.93883125 1.20623733 0.295524916
Indiana -0.13500142 -0.69308401 -0.03730631 -0.024769429
Iowa -1.28297267 -1.37704849 -0.58999237 -1.060387812
Kansas -0.41051452 -0.66908525 0.03177945 -0.345063775
Kentucky 0.43898421 -0.74108152 -0.93542116 -0.526563903
Louisiana 1.74767144 0.93883125 0.03177945 0.103348309
Maine -1.30593210 -1.05306531 -1.00450692 -1.434064548
Maryland 0.80633501 1.55079947 0.10086521 0.701231086
Massachusetts -0.77786532 -0.26110644 1.34440885 -0.526563903
Michigan 0.99001041 1.01082751 0.58446551 1.480613993
Minnesota -1.16817555 -1.18505846 0.03177945 -0.676034598
Mississippi 1.90838741 1.05882502 -1.48810723 -0.441152078
Missouri 0.27826823 0.08687549 0.30812248 0.743936999
Montana -0.41051452 -0.74108152 -0.86633540 -0.515887425
Nebraska -0.80082475 -0.82507715 -0.24456358 -0.505210947
Nevada 1.01296983 0.97482938 1.06806582 2.644350114
New Hampshire -1.30593210 -1.36504911 -0.65907813 -1.252564419
New Jersey -0.08908257 -0.14111267 1.62075188 -0.259651949
New Mexico 0.82929443 1.37080881 0.30812248 1.160319648
New York 0.76041616 0.99882813 1.41349461 0.519730957
North Carolina 1.19664523 1.99477641 -1.41902147 -0.547916860
North Dakota -1.60440462 -1.50904164 -1.48810723 -1.487446939
Ohio -0.11204199 -0.60908837 0.65355127 0.017936483
Oklahoma -0.27275797 -0.23710769 0.16995096 -0.131534211
Oregon -0.66306820 -0.14111267 0.10086521 0.861378259
Pennsylvania -0.34163624 -0.77707965 0.44629400 -0.676034598
Rhode Island -1.00745957 0.03887798 1.48258036 -1.380682157
South Carolina 1.51807718 1.29881255 -1.21176419 0.135377743
South Dakota -0.91562187 -1.01706718 -1.41902147 -0.900240639
Tennessee 1.24256408 0.20686926 -0.45182086 0.605142783
Texas 1.12776696 0.36286116 0.99898006 0.455672088
Utah -1.05337842 -0.60908837 0.99898006 0.178083656
Vermont -1.28297267 -1.47304350 -2.31713632 -1.071064290
Virginia 0.16347111 -0.17711080 -0.17547783 -0.056798864
Washington -0.86970302 -0.30910395 0.51537975 0.530407436
West Virginia -0.47939280 -1.07706407 -1.83353601 -1.273917376
Wisconsin -1.19113497 -1.41304662 0.03177945 -1.113770203
Wyoming -0.22683912 -0.11711392 -0.38273510 -0.601299251
attr(,"scaled:center")
Murder Assault UrbanPop Rape
7.788 170.760 65.540 21.232
attr(,"scaled:scale")
Murder Assault UrbanPop Rape
4.355510 83.337661 14.474763 9.366385 - calculamos las componentes principales
Aplicamos el análisis de componentes principales a las variables estandarizadas. Esto último equivale a trabajar con la matriz de correlaciones, en lugar de la matriz de covarianzas. Se estandariza para que variables con varianza alta no influyan demasiado en el estudio.
acp=prcomp(USArrests, scale = TRUE) #se hace el ACP con los datos estandarizados
acpStandard deviations (1, .., p=4):
[1] 1.5748783 0.9948694 0.5971291 0.4164494
Rotation (n x k) = (4 x 4):
PC1 PC2 PC3 PC4
Murder -0.5358995 -0.4181809 0.3412327 0.64922780
Assault -0.5831836 -0.1879856 0.2681484 -0.74340748
UrbanPop -0.2781909 0.8728062 0.3780158 0.13387773
Rape -0.5434321 0.1673186 -0.8177779 0.08902432Nos devuelve la desviacíon típica de cada componente principal y la matriz de paso en la diagonalización ortogonal con los autovectores dispuestos por columnas que se llama rotation en la instrucción prcomp.
summary(acp)Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.5749 0.9949 0.59713 0.41645
Proportion of Variance 0.6201 0.2474 0.08914 0.04336
Cumulative Proportion 0.6201 0.8675 0.95664 1.00000Square roots of los valores propios se muestran en la primera línea, mientras que la segunda y la tercera presentan, respectivamente, la proporción de varianza explicada por cada componente (obsérvese que, como era de esperar, ésta disminuye a medida que avanzamos en la estimación), y la varianza acumulada explicada.
Más información en detalle:
Con esta instrucción vemos toda la información que nos puede devolver prcomp
names(acp)[1] "sdev" "rotation" "center" "scale" "x" center y scale se corresponden con las medias y las desviaciones típicas originales de las variables previo estandarización e implementación del ACP.
acp$center Murder Assault UrbanPop Rape
7.788 170.760 65.540 21.232 acp$scale Murder Assault UrbanPop Rape
4.355510 83.337661 14.474763 9.366385 acp$scale^2 Murder Assault UrbanPop Rape
18.97047 6945.16571 209.51878 87.72916 En los datos originales la varianza de Assault es muy alta y eso puede influir mucho en el estudio de la ACP. Por eso se estandarizan las variables.
acp$rotation PC1 PC2 PC3 PC4
Murder -0.5358995 -0.4181809 0.3412327 0.64922780
Assault -0.5831836 -0.1879856 0.2681484 -0.74340748
UrbanPop -0.2781909 0.8728062 0.3780158 0.13387773
Rape -0.5434321 0.1673186 -0.8177779 0.08902432La matriz rotation es la matriz de paso. Cada columna proporciona para cada componente principal el autovector, es decir los \(a_{ji}\). Son los coeficientes que proporcionan la combinación lineal de las variables \(X_i\). Así nos da idea del peso/importancia que cada variable original tiene en la componente principal. Se les suelen llamar cargas o loadings según el método.
Si multiplicáramos la matriz de paso por la matriz de los datos originales, obtenemos las coordenadas de los datos en el nuevo sistema rotado de coordenadas que es justo lo que proporciona la matriz x (scores). Es decir, Y=AX siendo Y la x, A la matriz rotation y X la matriz de datos originales USArrests.
sdev son las desviaciones de cada componente principal. Para obtener los atuovalores por cada componente principal la obtenemos elevando al cuadrado la desviación estándar. Estos son los autovalores.
acp$sdev^2[1] 2.4802416 0.9897652 0.3565632 0.1734301#Varianza total es la suma de todos los autovalores
sum(acp$sdev^2)[1] 4Ahora representamos las varianzas de cada componente principal, es decir, los autovalores:
Se llama gráfico de sedimentación y se usa para decidir cuántas componentes principales nos quedamos. En este caso nos quedaríamos solo con las dos primeras componentes principales.
plot(acp)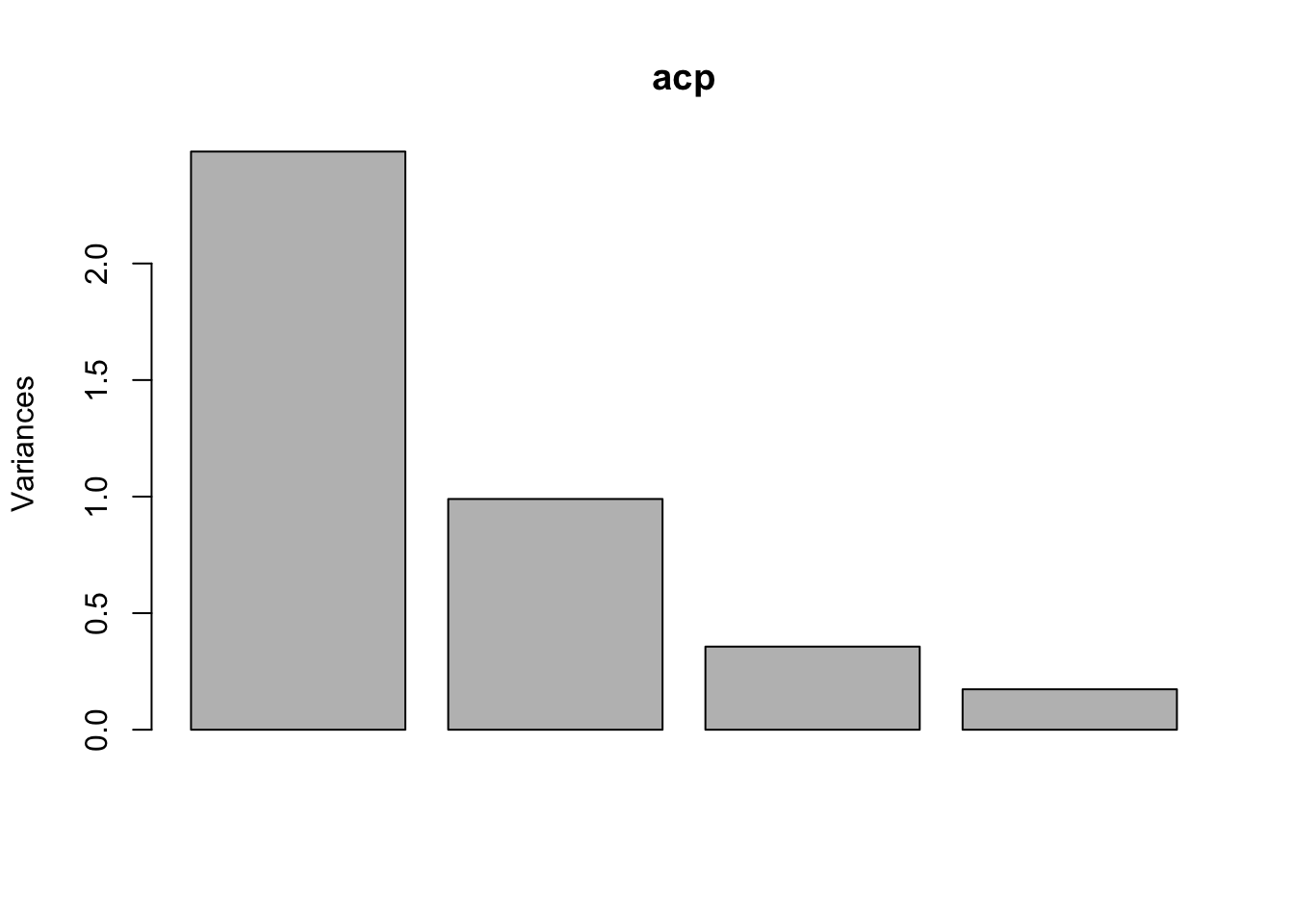
Otra forma de representarlo
plot(acp, type="l")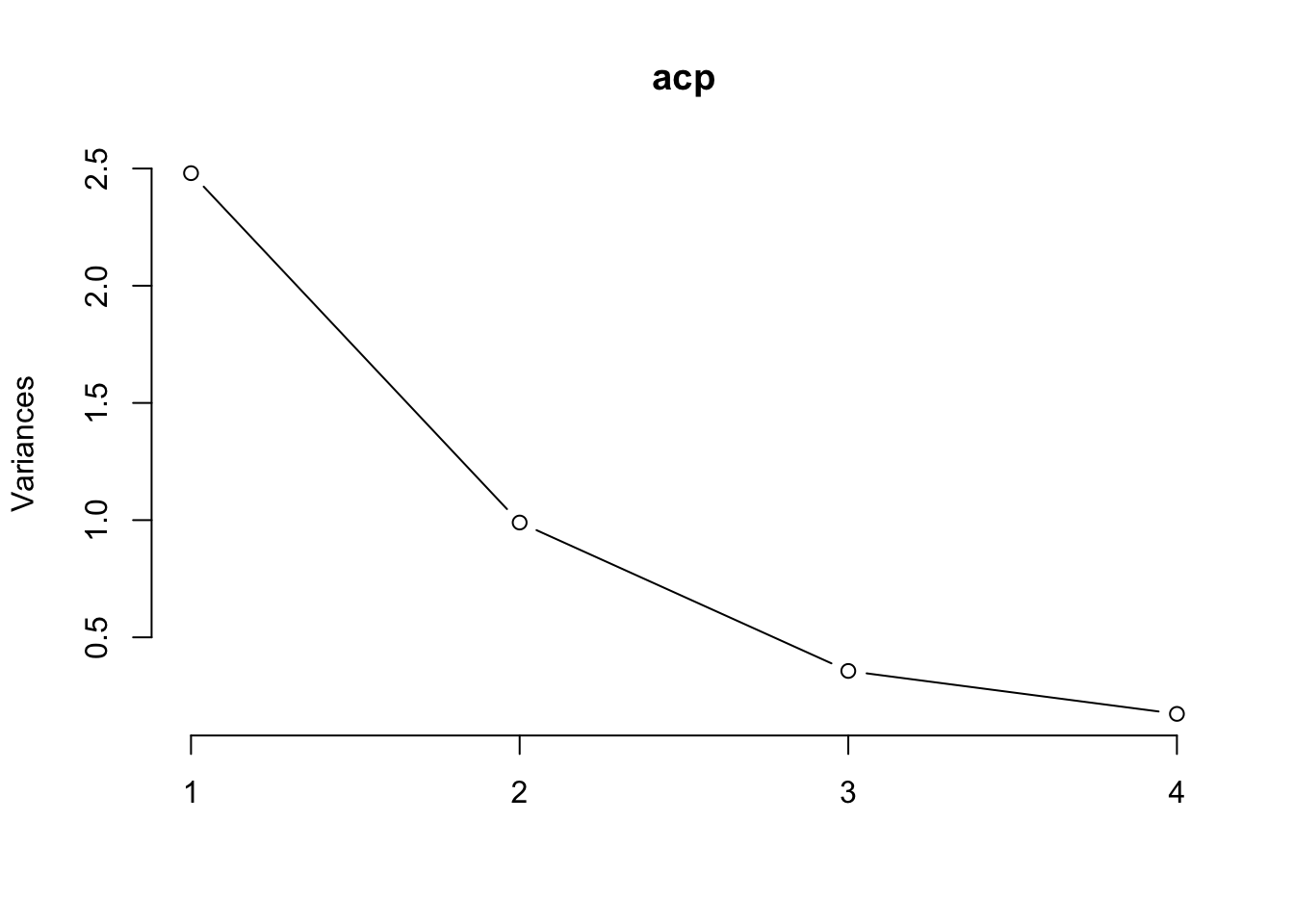
La siguiente instrucción nos da para cada componente principal la desviación típica, la proporción de la varianza explicada para cada componente (recuerdo que era autovalor dividido entre la suma de los autovalores o equivalentemente varianza de la componente principal dividido por la varianza total).
Por ejemplo para la primera obtenemos \(0.6201=2.4802416/4\)
También nos da la proporción acumulada. Esto también se utiliza para elegir cuántas componentes principales nos quedamos, mirando la varianza acumulada y quedándonos con las componentes que expliquen un 80 o 90 por cierto de los datos.
summary(acp)Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.5749 0.9949 0.59713 0.41645
Proportion of Variance 0.6201 0.2474 0.08914 0.04336
Cumulative Proportion 0.6201 0.8675 0.95664 1.00000Podemos representar la Proporción acumulada de varianza explicada para elegir el número de componentes con las que quedarnos.
plot(cumsum(acp$sdev^2/sum(acp$sdev^2)),xlab = "Componente Principal",ylab = "Cumulative proportion of Variance Explained",ylim = c(0,1),type="b")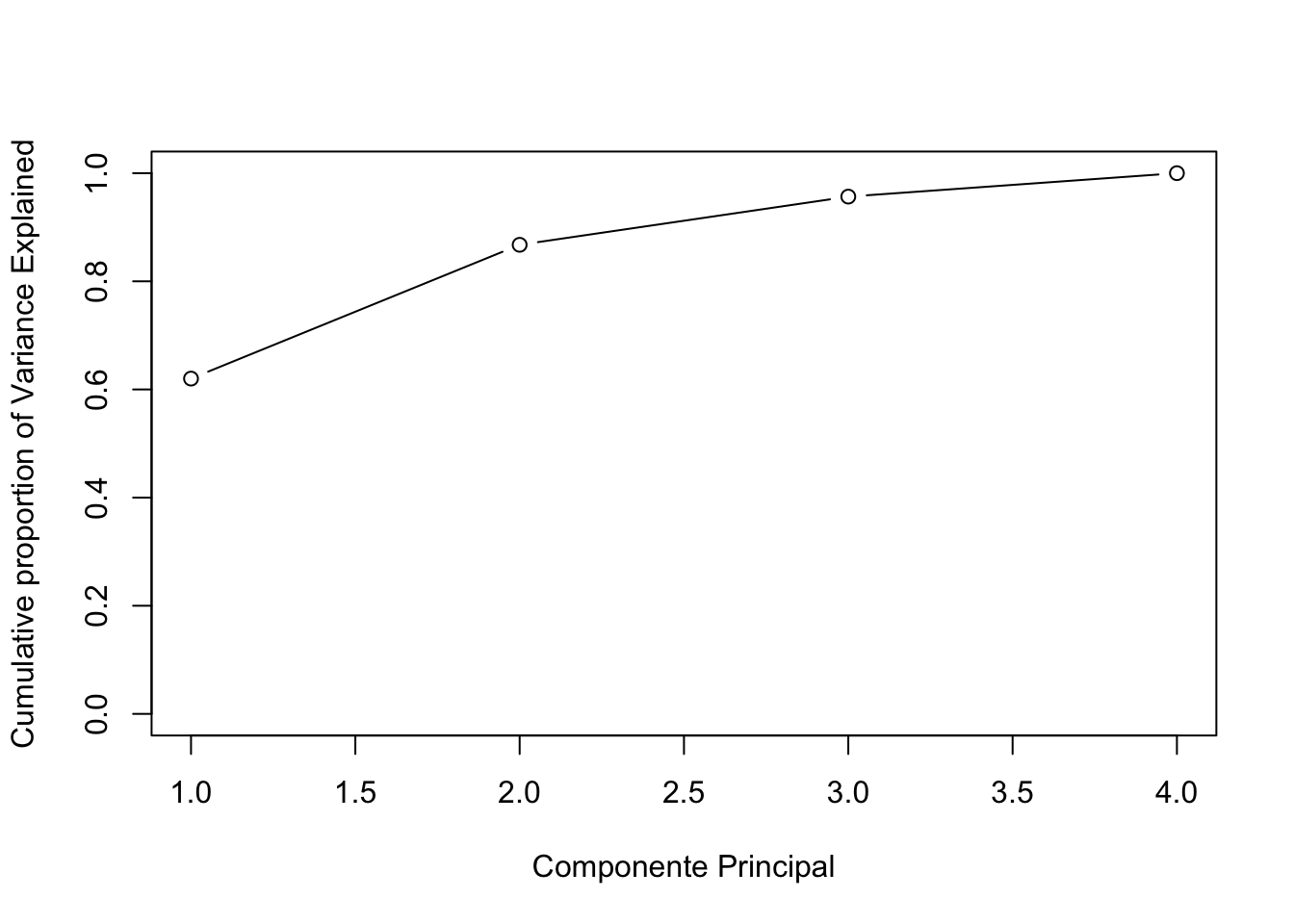
Otro gráfico para representar la varianza explicada (la proporción de varizanza)
library(ggplot2)
library(factoextra) Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBafviz_eig(acp) #representa lo mismo que la función fviz_screeplot(acp) 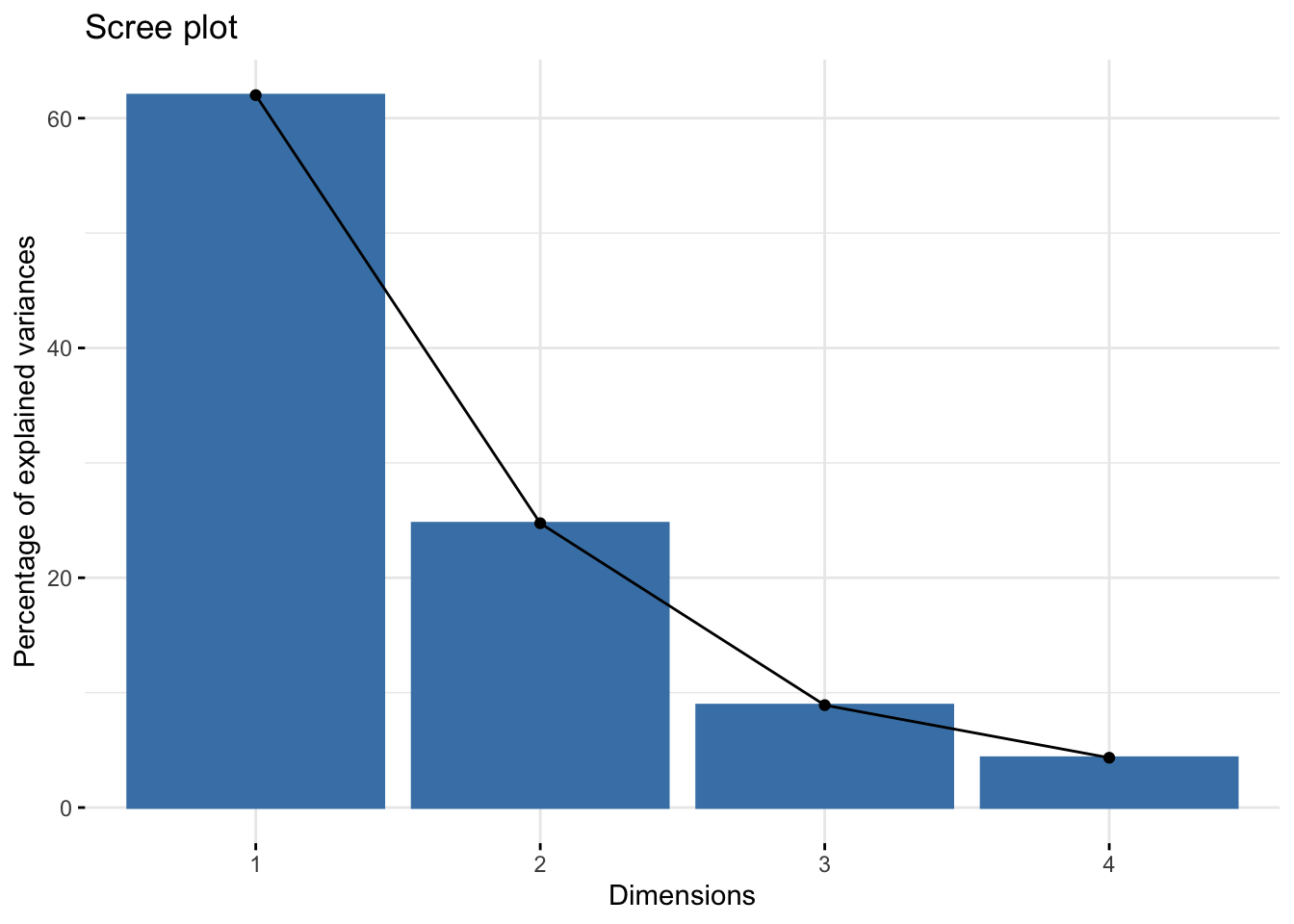
Para calcular los nuevos valores de las observaciones tendríamos que hacer esta operación por ejemplo para el valor de Alabama en la primera componente sería así. La primera columna de la matriz rotation es el vector propio y por tanto la combinación lineal para PC1 sería
\[PC1_{Alabama}=-0.5358995 * Murder_{Alabama} -0.5831836 * Assault_{Alabama} -0.2781909 * UrbanPop_{Alabama} -0.5434321 * Rape_{Alabama}\]
PC1Alabama=-0.5358995 * 1.24256408 -0.5831836 * 0.78283935 -0.2781909 * -0.52090661 -0.5434321 * -0.003416473
PC1Alabama[1] -0.9756604Esto ha sido para un solo valor, con la siguiente instrucción conseguimos todos los valores
acp$x #devuelve el calculo AX para darnos la matriz Y. Nos da la nueva base de datos teniendo las 50 observaciones (los 50 estados) con las nuevas variables (columnas) CP1,CP2,CP3 y CP4. PC1 PC2 PC3 PC4
Alabama -0.97566045 -1.12200121 0.43980366 0.154696581
Alaska -1.93053788 -1.06242692 -2.01950027 -0.434175454
Arizona -1.74544285 0.73845954 -0.05423025 -0.826264240
Arkansas 0.13999894 -1.10854226 -0.11342217 -0.180973554
California -2.49861285 1.52742672 -0.59254100 -0.338559240
Colorado -1.49934074 0.97762966 -1.08400162 0.001450164
Connecticut 1.34499236 1.07798362 0.63679250 -0.117278736
Delaware -0.04722981 0.32208890 0.71141032 -0.873113315
Florida -2.98275967 -0.03883425 0.57103206 -0.095317042
Georgia -1.62280742 -1.26608838 0.33901818 1.065974459
Hawaii 0.90348448 1.55467609 -0.05027151 0.893733198
Idaho 1.62331903 -0.20885253 -0.25719021 -0.494087852
Illinois -1.36505197 0.67498834 0.67068647 -0.120794916
Indiana 0.50038122 0.15003926 -0.22576277 0.420397595
Iowa 2.23099579 0.10300828 -0.16291036 0.017379470
Kansas 0.78887206 0.26744941 -0.02529648 0.204421034
Kentucky 0.74331256 -0.94880748 0.02808429 0.663817237
Louisiana -1.54909076 -0.86230011 0.77560598 0.450157791
Maine 2.37274014 -0.37260865 0.06502225 -0.327138529
Maryland -1.74564663 -0.42335704 0.15566968 -0.553450589
Massachusetts 0.48128007 1.45967706 0.60337172 -0.177793902
Michigan -2.08725025 0.15383500 -0.38100046 0.101343128
Minnesota 1.67566951 0.62590670 -0.15153200 0.066640316
Mississippi -0.98647919 -2.36973712 0.73336290 0.213342049
Missouri -0.68978426 0.26070794 -0.37365033 0.223554811
Montana 1.17353751 -0.53147851 -0.24440796 0.122498555
Nebraska 1.25291625 0.19200440 -0.17380930 0.015733156
Nevada -2.84550542 0.76780502 -1.15168793 0.311354436
New Hampshire 2.35995585 0.01790055 -0.03648498 -0.032804291
New Jersey -0.17974128 1.43493745 0.75677041 0.240936580
New Mexico -1.96012351 -0.14141308 -0.18184598 -0.336121113
New York -1.66566662 0.81491072 0.63661186 -0.013348844
North Carolina -1.11208808 -2.20561081 0.85489245 -0.944789648
North Dakota 2.96215223 -0.59309738 -0.29824930 -0.251434626
Ohio 0.22369436 0.73477837 0.03082616 0.469152817
Oklahoma 0.30864928 0.28496113 0.01515592 0.010228476
Oregon -0.05852787 0.53596999 -0.93038718 -0.235390872
Pennsylvania 0.87948680 0.56536050 0.39660218 0.355452378
Rhode Island 0.85509072 1.47698328 1.35617705 -0.607402746
South Carolina -1.30744986 -1.91397297 0.29751723 -0.130145378
South Dakota 1.96779669 -0.81506822 -0.38538073 -0.108470512
Tennessee -0.98969377 -0.85160534 -0.18619262 0.646302674
Texas -1.34151838 0.40833518 0.48712332 0.636731051
Utah 0.54503180 1.45671524 -0.29077592 -0.081486749
Vermont 2.77325613 -1.38819435 -0.83280797 -0.143433697
Virginia 0.09536670 -0.19772785 -0.01159482 0.209246429
Washington 0.21472339 0.96037394 -0.61859067 -0.218628161
West Virginia 2.08739306 -1.41052627 -0.10372163 0.130583080
Wisconsin 2.05881199 0.60512507 0.13746933 0.182253407
Wyoming 0.62310061 -0.31778662 0.23824049 -0.164976866#Como hemos decidido quedarnos con la primera y segunda componente nuestros datos finales serían. Esta es la solución final
acp$x[,c(1,2)] PC1 PC2
Alabama -0.97566045 -1.12200121
Alaska -1.93053788 -1.06242692
Arizona -1.74544285 0.73845954
Arkansas 0.13999894 -1.10854226
California -2.49861285 1.52742672
Colorado -1.49934074 0.97762966
Connecticut 1.34499236 1.07798362
Delaware -0.04722981 0.32208890
Florida -2.98275967 -0.03883425
Georgia -1.62280742 -1.26608838
Hawaii 0.90348448 1.55467609
Idaho 1.62331903 -0.20885253
Illinois -1.36505197 0.67498834
Indiana 0.50038122 0.15003926
Iowa 2.23099579 0.10300828
Kansas 0.78887206 0.26744941
Kentucky 0.74331256 -0.94880748
Louisiana -1.54909076 -0.86230011
Maine 2.37274014 -0.37260865
Maryland -1.74564663 -0.42335704
Massachusetts 0.48128007 1.45967706
Michigan -2.08725025 0.15383500
Minnesota 1.67566951 0.62590670
Mississippi -0.98647919 -2.36973712
Missouri -0.68978426 0.26070794
Montana 1.17353751 -0.53147851
Nebraska 1.25291625 0.19200440
Nevada -2.84550542 0.76780502
New Hampshire 2.35995585 0.01790055
New Jersey -0.17974128 1.43493745
New Mexico -1.96012351 -0.14141308
New York -1.66566662 0.81491072
North Carolina -1.11208808 -2.20561081
North Dakota 2.96215223 -0.59309738
Ohio 0.22369436 0.73477837
Oklahoma 0.30864928 0.28496113
Oregon -0.05852787 0.53596999
Pennsylvania 0.87948680 0.56536050
Rhode Island 0.85509072 1.47698328
South Carolina -1.30744986 -1.91397297
South Dakota 1.96779669 -0.81506822
Tennessee -0.98969377 -0.85160534
Texas -1.34151838 0.40833518
Utah 0.54503180 1.45671524
Vermont 2.77325613 -1.38819435
Virginia 0.09536670 -0.19772785
Washington 0.21472339 0.96037394
West Virginia 2.08739306 -1.41052627
Wisconsin 2.05881199 0.60512507
Wyoming 0.62310061 -0.31778662Vamos a ver ahora algunas representaciones de nuestros resultados para poder interpretarlos.
Con biplot se representa la primera componente principal contra la segunda componente principal y la nueva base de datos acp$x[,c(1,2)]
biplot(prcomp(USArrests, scale = TRUE))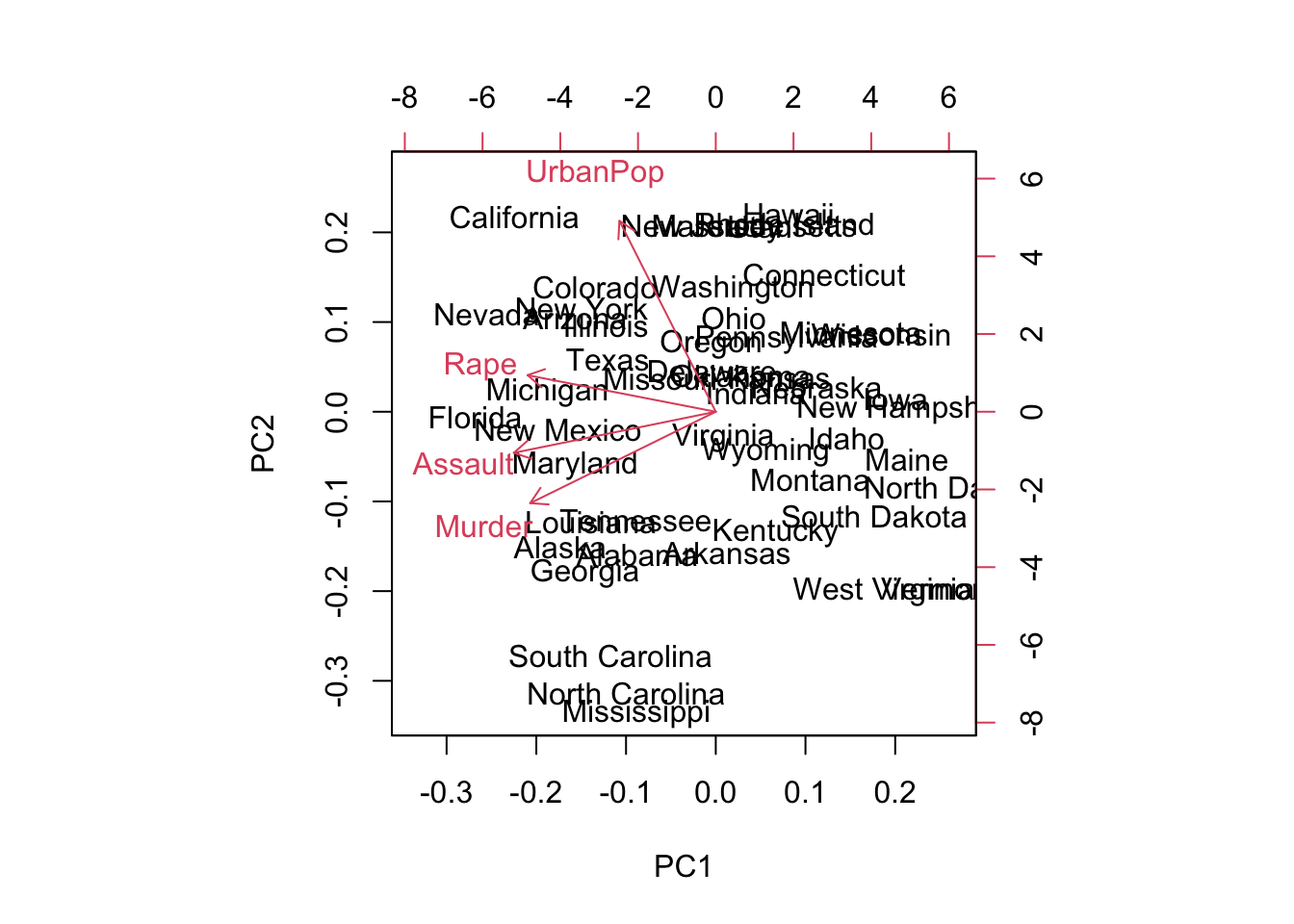
El biplot es una representación gráfica simultánea de los observaciones de la base de datos (mediante puntos) y las variables (mediante flechas), en un mismo sistema de coordenadas bidimensional construido en base a las dos primeras componentes principales. Permite interpretar el significado de las componentes (la primera en el eje horizontal y la segunda en el eje vertical) en base a las direcciones de las flechas. A su vez, se valoran como parecidas son las observaciones cuyos puntos están próximos en el biplot.
El biplot se interpreta teniendo en cuenta estas consideraciones. Para los vectores (variables originales), nos fijamos en su longitud y en el ángulo con respecto a los ejes de las componentes principales y entre ellos mismos:
Ángulo: cuanto más paralelo es un vector al eje de una componente, más ha contribuido a la creación de la misma. Con ello obtienes información sobre qué variable(s) ha sido más determinante para crear cada componente, y si entre las variables (y cuales) hay correlaciones.
Longitud: cuanto mayor la longitud de un vector relacionado con la variable (en un rango normalizado de 0 a 1), mayor variabilidad de dicha variable está contenida en la representación de las dos componentes del biplot, es decir, mejor está representada su información en el gráfico.
Ángulos pequeños entre vectores representa alta correlación entre las variables implicadas (observaciones con valores altos en una de esas variables tendrá valores altos en la variable o variables correlacionadas); ángulos rectos representan falta de correlación, y ángulos opuestos representan correlación negativa (una observación con valores altos en una de las variables irá acompañado de valores bajos en la otra).Entonces en nuestro ejemplo si miramos la matriz rotation en valor absoluto Murder, Assault y Rape pesan mucho en PC1. En el biplot estas tres explican mucho PC1 porque se mueven mucho hacia la izquierda en el eje de PC1 desde el origen (son casi paralelos al eje PC1). Sin embargo para la PC2 se ve que la variable UrbanPop es la que tiene mayor valor absoluto con lo que es la que más peso tiene y explica mejor PC2. En el biplot se ve que el vector es casi paralelo a PC2.
Además en el biplot vemos la representación de cada observación (en nuestro ejemplo los estados de EEUU). Para los scores (observaciones), nos fijamos en los posibles agrupamientos. Puntuaciones próximas representan observaciones de similares características. Puntuaciones con valores de las variables próximas a la media se sitúan más cerca del centro del biplot (0, 0). El resto representan variabilidades normales o extremas (outliers). Por otro lado, la relación de las observaciones con las variables se puede estudiar proyectando las observaciones sobre la dirección de los vectores.
Los estados que se encuentran en el lado negativo de PC1 les influye más Murder Asault y Rape. Los estados que se encuentran en la parte negativa de PC2 son los estados que les influye más la variable UrbanPop.
En las dos siguientes gráficas se representan de forma más clara por separado las observaciones de las componentes principales
fviz_pca_ind(acp) #se representan de forma más clara las observaciones.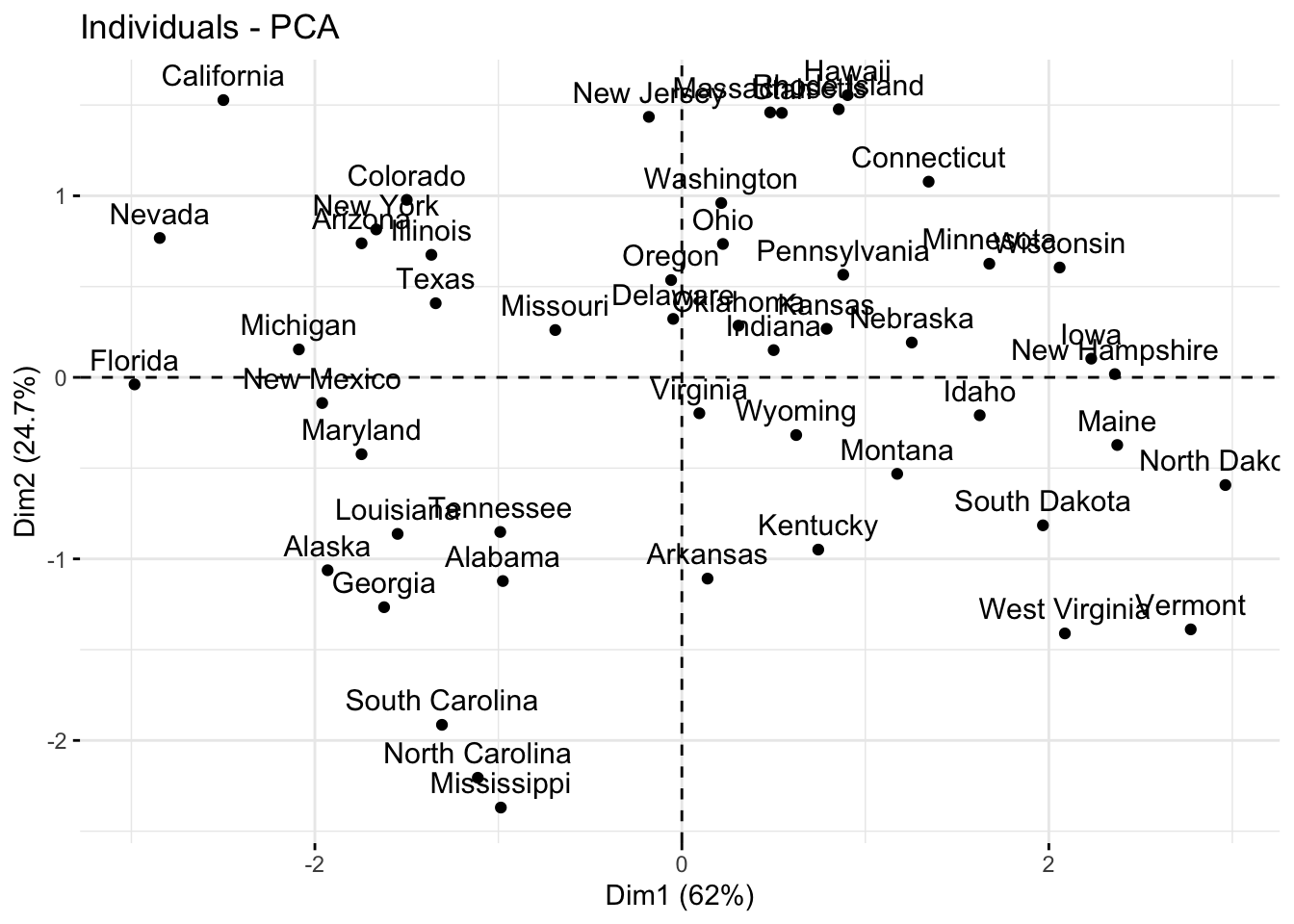
fviz_pca_var(acp) #componentes principales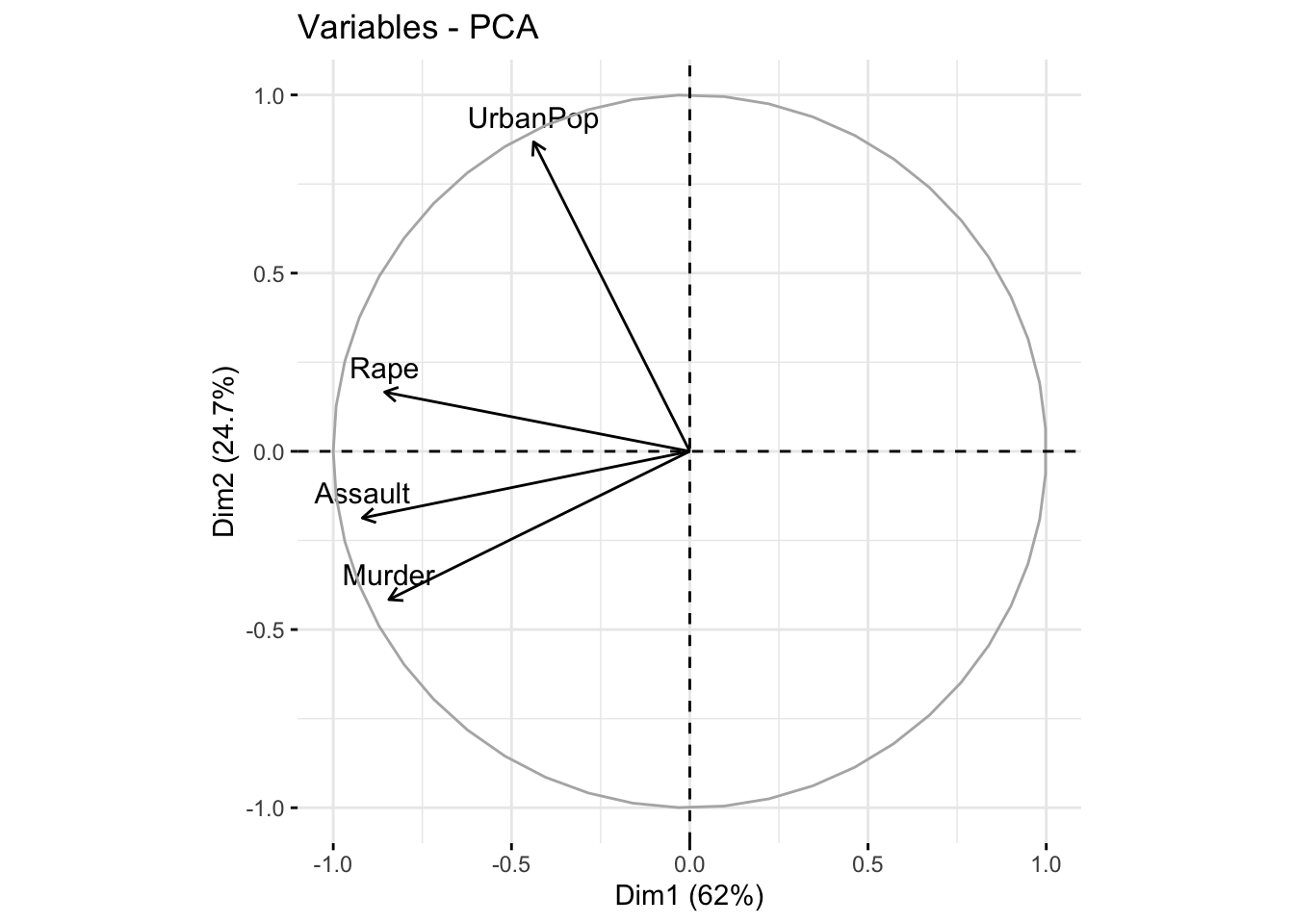
En las siguientes gráficas vamos a ver la influencia de las variables sobre la primera y segunda componenente respectivamente que habíamos comentado anteriormente.
La línea roja discontinua indica el valor promedio esperado, si las contribuciones fueran uniformes. La línea roja señala el valor de 1/número de categoriás, que sería la contribución promedio si todas contribuyeran igual. Solo las que superan ese valor se considera que tienen una contribución razonable.
fviz_contrib(acp,choice = "var",axes = 1)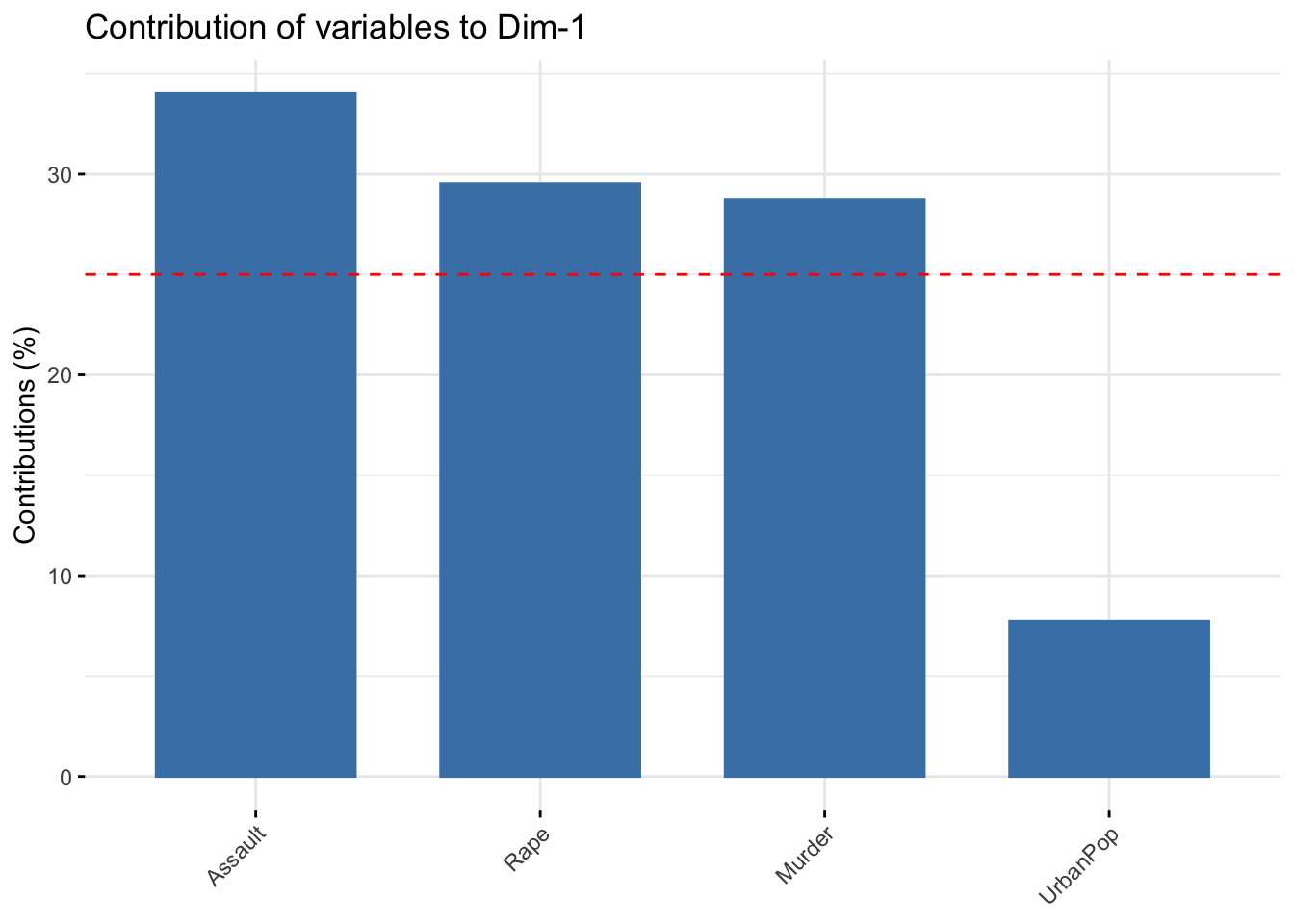
fviz_contrib(acp,choice = "var",axes = 2)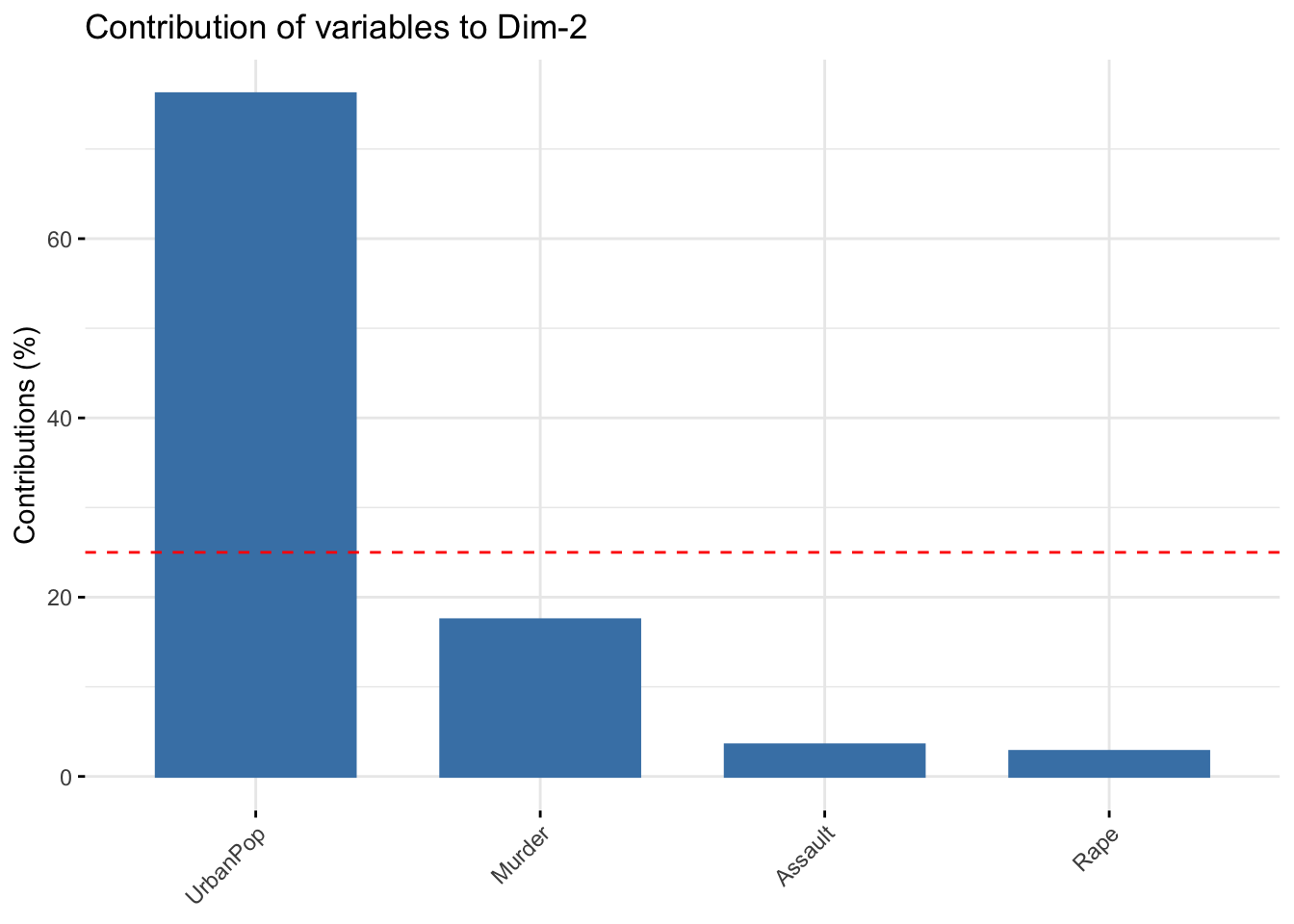
En estas dos gráficas se muestra la influencia de las obervaciones en las componentes primera y segunda respectivamente. Esto también se observaba en la gráfica biplot pero ahora se muestra más detalladamente.
fviz_contrib(acp,choice = "ind",axes = 1,top = 10)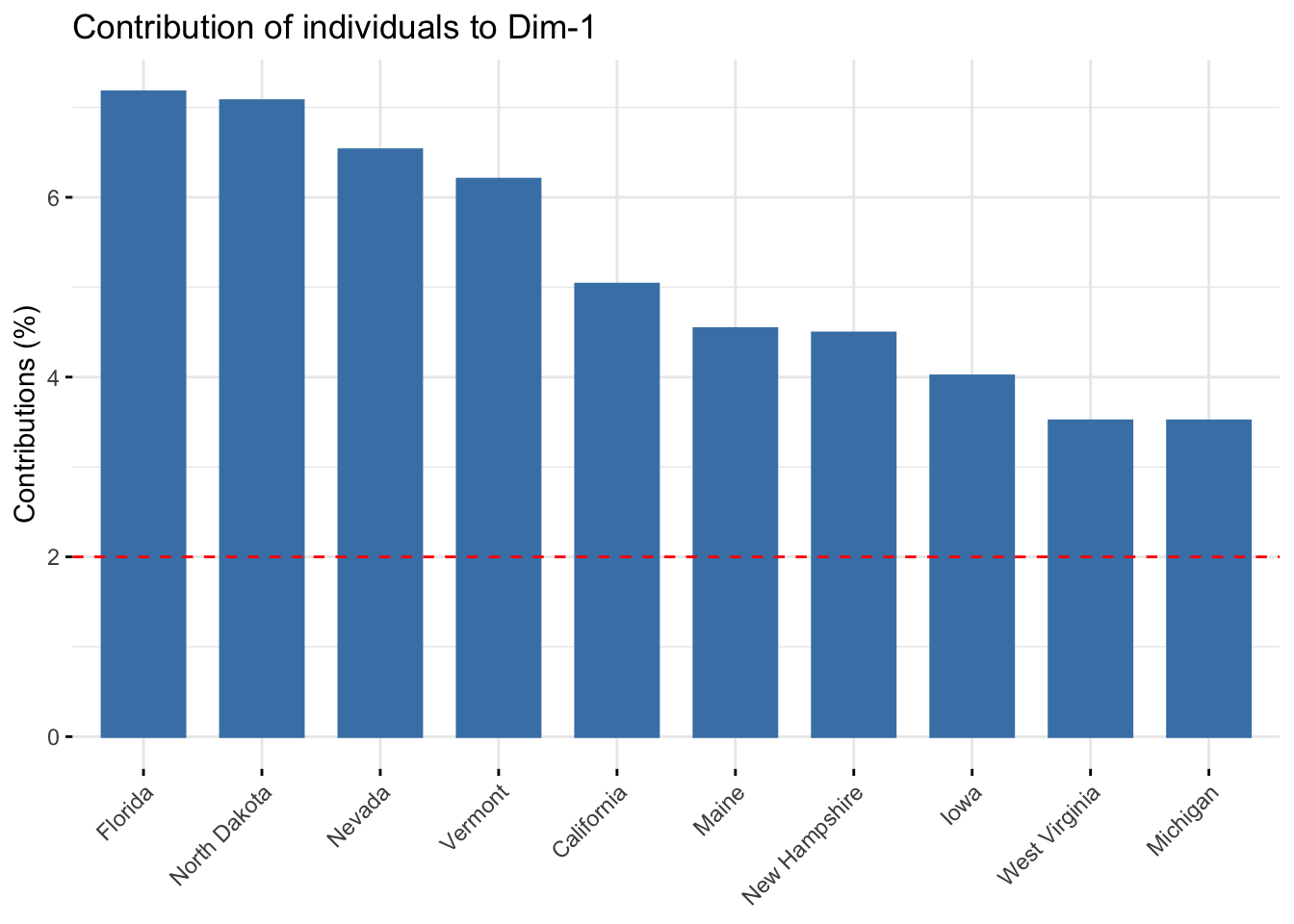
fviz_contrib(acp,choice = "ind",axes = 2,top=10)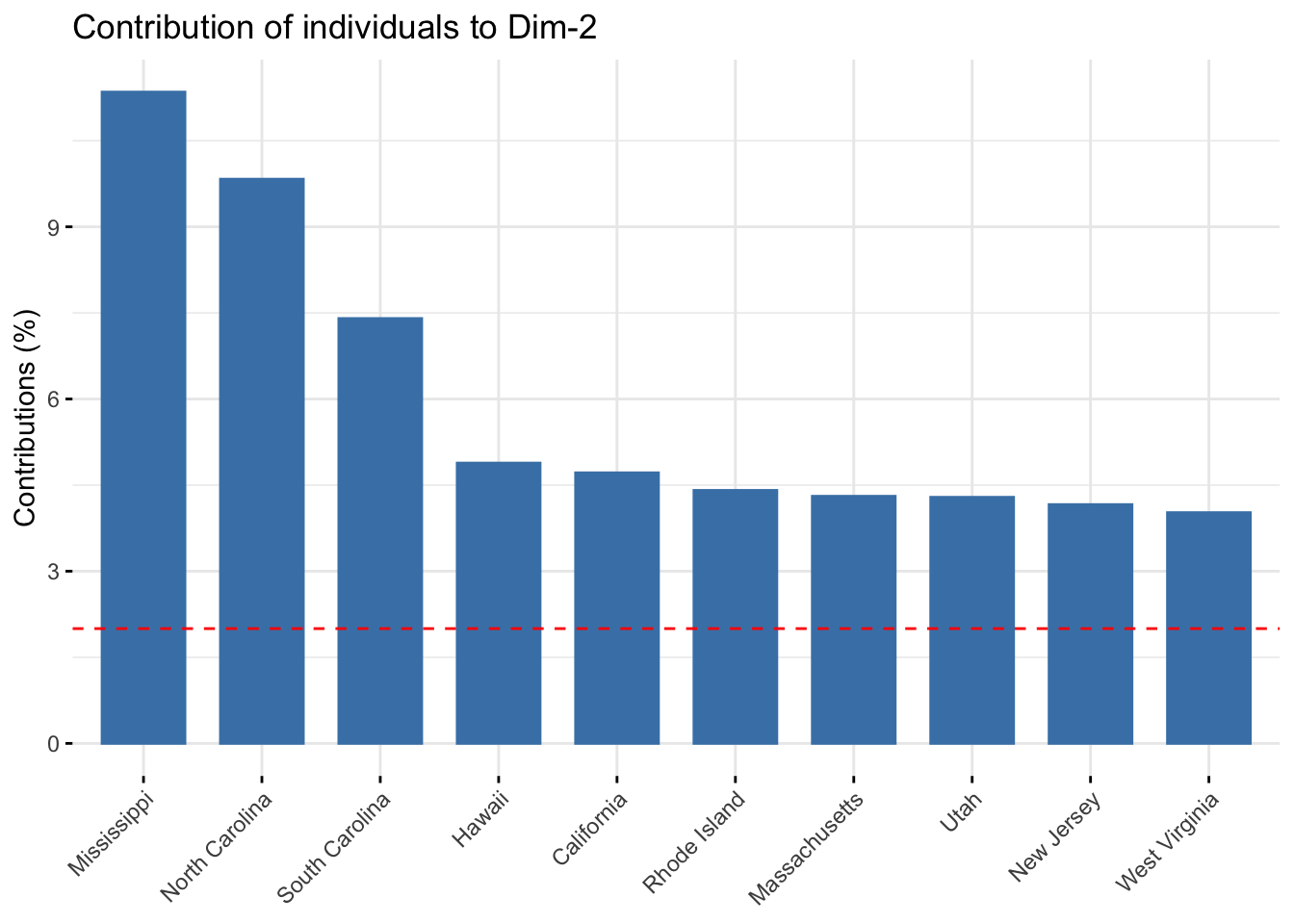
Ahora veremos cómo hubiéramos calculado de forma directa las componentes principales sin hacer uso de ninguna instrucción predefinida. Realmente lo que se está haciendo es una diagonalización ortogonal.
stand2=scale(USArrests,center = TRUE,scale=TRUE) #primero estandarizamos los datos
diagortg=eigen(cov(stand2)) #calculamos los autovalores y autovectores de las matriz de covarianza
t_eigenvectors <- t(diagortg$vectors) #trasponemos la matriz de autovectores (autovectores por filas=componentes x variables)
t_datos_estand <- t(stand2) #traspuesta de los datos originales estandarizados #variables x estadosUSA
datos_cp <- t_eigenvectors %*% t_datos_estand #los nuevos datos, componenntes x estadosUSA. Hemos calculado Y=AX
t(datos_cp) #volvemos a trasponer la matriz para tener la nueva matriz de datos formados , estadosUSA x componentes [,1] [,2] [,3] [,4]
Alabama 0.97566045 1.12200121 -0.43980366 0.154696581
Alaska 1.93053788 1.06242692 2.01950027 -0.434175454
Arizona 1.74544285 -0.73845954 0.05423025 -0.826264240
Arkansas -0.13999894 1.10854226 0.11342217 -0.180973554
California 2.49861285 -1.52742672 0.59254100 -0.338559240
Colorado 1.49934074 -0.97762966 1.08400162 0.001450164
Connecticut -1.34499236 -1.07798362 -0.63679250 -0.117278736
Delaware 0.04722981 -0.32208890 -0.71141032 -0.873113315
Florida 2.98275967 0.03883425 -0.57103206 -0.095317042
Georgia 1.62280742 1.26608838 -0.33901818 1.065974459
Hawaii -0.90348448 -1.55467609 0.05027151 0.893733198
Idaho -1.62331903 0.20885253 0.25719021 -0.494087852
Illinois 1.36505197 -0.67498834 -0.67068647 -0.120794916
Indiana -0.50038122 -0.15003926 0.22576277 0.420397595
Iowa -2.23099579 -0.10300828 0.16291036 0.017379470
Kansas -0.78887206 -0.26744941 0.02529648 0.204421034
Kentucky -0.74331256 0.94880748 -0.02808429 0.663817237
Louisiana 1.54909076 0.86230011 -0.77560598 0.450157791
Maine -2.37274014 0.37260865 -0.06502225 -0.327138529
Maryland 1.74564663 0.42335704 -0.15566968 -0.553450589
Massachusetts -0.48128007 -1.45967706 -0.60337172 -0.177793902
Michigan 2.08725025 -0.15383500 0.38100046 0.101343128
Minnesota -1.67566951 -0.62590670 0.15153200 0.066640316
Mississippi 0.98647919 2.36973712 -0.73336290 0.213342049
Missouri 0.68978426 -0.26070794 0.37365033 0.223554811
Montana -1.17353751 0.53147851 0.24440796 0.122498555
Nebraska -1.25291625 -0.19200440 0.17380930 0.015733156
Nevada 2.84550542 -0.76780502 1.15168793 0.311354436
New Hampshire -2.35995585 -0.01790055 0.03648498 -0.032804291
New Jersey 0.17974128 -1.43493745 -0.75677041 0.240936580
New Mexico 1.96012351 0.14141308 0.18184598 -0.336121113
New York 1.66566662 -0.81491072 -0.63661186 -0.013348844
North Carolina 1.11208808 2.20561081 -0.85489245 -0.944789648
North Dakota -2.96215223 0.59309738 0.29824930 -0.251434626
Ohio -0.22369436 -0.73477837 -0.03082616 0.469152817
Oklahoma -0.30864928 -0.28496113 -0.01515592 0.010228476
Oregon 0.05852787 -0.53596999 0.93038718 -0.235390872
Pennsylvania -0.87948680 -0.56536050 -0.39660218 0.355452378
Rhode Island -0.85509072 -1.47698328 -1.35617705 -0.607402746
South Carolina 1.30744986 1.91397297 -0.29751723 -0.130145378
South Dakota -1.96779669 0.81506822 0.38538073 -0.108470512
Tennessee 0.98969377 0.85160534 0.18619262 0.646302674
Texas 1.34151838 -0.40833518 -0.48712332 0.636731051
Utah -0.54503180 -1.45671524 0.29077592 -0.081486749
Vermont -2.77325613 1.38819435 0.83280797 -0.143433697
Virginia -0.09536670 0.19772785 0.01159482 0.209246429
Washington -0.21472339 -0.96037394 0.61859067 -0.218628161
West Virginia -2.08739306 1.41052627 0.10372163 0.130583080
Wisconsin -2.05881199 -0.60512507 -0.13746933 0.182253407
Wyoming -0.62310061 0.31778662 -0.23824049 -0.1649768669 Bibliografia
https://rpubs.com/gabrielmartos/multivPCA primera aproximación
https://rpubs.com/Joaquin_AR/287787 aparece como sería el calculo directo de PCA y una aplicación a regresión lineal
http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/118-principal-component-analysis-in-r-prcomp-vs-princomp/ diferencias entre las dos instrucciones y gráficas fviz muy completo
http://www.diegocalvo.es/acp-analisis-de-componentes-principales-en-r/ para los graficos por parejas de las comp. principales
https://bookdown.org/content/2274/portada.html más amplio y con regresion y analisis factorial
https://www.youtube.com/watch?v=6BeuHCo1gZQ explicado con usarrests